我们把数据类型分为基本数据类型与高级数据类型,基本数据类型中有:整数,浮点数,字符,指针,数组(已经定义好的),而高级数据类型:像结构体,共用体,枚举等。
链表与数组
相同点:
链表与数组都是按顺序存储若干个相同数据类型或相同成员的结构体
不同点:
●数组各个元素的空间必须连续,而链表各个元素的空间不一定连续,可以分散存储在内存中。
●查找数组元素,只需要给出下标,而查找链表元素,需要根据链表的首结点记录地址,顺序查找下去;
●删除数组一个非尾部的元素,就要将后面的元素依次向前移动,以保证数组空间的连续性,而删除链表中的一个节点,只需要修改删除节点前后的指针。
【链表的好处】
●不需要预先分配存储空间;
●分配的空间可以根据程序的需要扩大和缩小;
●如果数据的数量不确定,或者经常变化,就要优先考虑使用链表;
●节约内存空间;
如果元素个数确定,优先使用数组,如果元素个数不确定,优先使用链表
【链表的存储结构】
链表的节点不仅包括元素值,也包括下一个元素的地址(数据域,指针域),即(元素,地址)
举个例子:如果链表包含四个元素,而首地址是1255,则:
结点的表示:元素值与下一个元素的地址
如上图:地址1255是结点自身的地址,不是指针域,Link1是数据域,1356是指向下一个结点的地址。
【链表是一个结构体】
1 | struct LinkNode |

同数组一样,链表名称即为首地址,不过链表是个指针类型的结构体变量
来个例子:用链表存放三个学生的信息
【遍历链表】
1.将链表h的各个节点的数据域输出
2.从第一个结点开始,只要p非空,就输出这个结点,并将p后移
我们为什么要把struct Link *h(头结点)作为函数的参数,因为我们在遍历链表的时候的顺序是从头到尾的,然后我们再将游标指针指向头结点struct Link *p=h;
【声明链表】
我们用head=NULL;或是用 !head,判断链表为空;用p=p->next;//把下一个地址的值赋给本身
【链表的插入操作】
当将一个值为x的结点s插入链表中,我们先用malloc函数动态申请内存,再赋值给s,s是插入点的指针;
【插入到链表的头部】
如图:头指针*head为1255,当把链表插入到头部后,我们的操作:
1 | s->next=head;//将s的下一个结点指向head |
【插入到链表的中部】
假如有一个指针p,p原先保存的地址是1356,而p->next是1475,但我们当将一个值为x的结点s插入链表中,如图:
1 | s->next=p->next;//s指针域指向原先p的指针域 |
【插入到链表的尾部】
如何把一个链表插入非空链表尾部?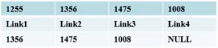
我们先要判断尾部!
直到p->next(指针域)为空值时,则到了链表的尾部,这是我们再将链表插入非空链表尾部。
具体实现:
1 | p=p->next;//如果p不是尾结点就往后移动 |
【删除链表的结点】
1.【删除表头结点,直接更改头指针head】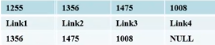
原head是头结点,地址是1255,指针域是1356,当我们删除第一个链表时,现在的head的地址变成1356,指针域是1475。即head=head->next;
2.【删除非表头结点】
删除前,假设指针p的地址是1475,pre(p的前驱结点)->next等价于p,也就是地址1475,而p->next==1008,当我们删除p的时候,于是pre(p的前驱结点)->next,从指向地址1475变为指向地址1008,即(pre->next=p->next),这时指针p变成野指针,应该释放掉。
【尾插法操作】
1 |
|
【头插法操作】
【共用体】
●使用共用体,使多个变量共享一块内存
●目地是为了节约内存空间
【共用体声明】
1 | union 共用体名 |
注意:初始化共用体只能给一个值的序列
另外共用体中不要包含指针成员,因为共用体的成员值很容易发生改变。